分类与回归树(Classification and regression trees, CART)是由四位美国统计学家于1970年提出的一种非常有效的非参数分类和回归的统计学方法。它通过构建二叉树达到预测目的,包括分类树和回归树。CART能同时进行样本的分类或回归与变量的选择。然而,CART算法具有不稳定性,即自变量X较小的变化可引起树结构很大的变化。蒙特卡罗采样后多次结果的统计值恰好具有提高结果稳定性这一优势。将蒙特卡罗与CART的分类树结合,就是蒙特卡罗树(Monte Carlo classification tree algorithm, MCTree)的方法[41],该方法可以同时用于样本分类与特征变量的选择。首先用蒙特卡罗随机分组技术将校正集产生很多校正子集和验证集,其中校正子集用来构建分类树,验证集使用模糊修剪策略对树进行修剪。每次的校正子集会产生一个分类树,从分类树可以得到样本的分类情况及跟分类相关的特征变量。将这多棵树的结果进行统计,每个变量重要性的平均值即为最终输出的变量重要性指标。



































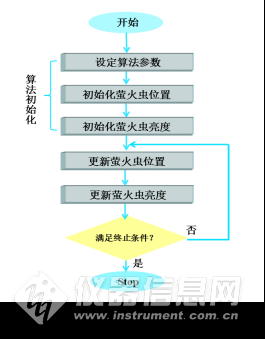 (5)萤火虫算法
(5)萤火虫算法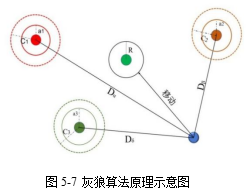 灰狼优化算法(GWO)是受灰狼群体捕食过程的启发,由澳大利亚学者Mirjalili等[35]在2014年提出来的一种群体智能优化算法。灰狼群居,在捕猎过程中它们分工明确、共同合作进行捕猎。领导能力最强的灰狼被记为α,主要负责捕猎过程中的决策部分及管理狼群。剩下的灰狼个体按社会等级被依次记为β,δ和ω。其中β狼和δ狼是等级依次排在后面的两个个体,捕猎中它们会协助α狼对灰狼群进行管理和辅助参与捕猎过程中的决策问题。剩余的狼群被定义为ω,其主要职责是平衡灰狼种群的内部关系及协助α,β,δ对猎物进行攻击。在整个捕猎过程中,首先由α狼带领狼群搜寻、追踪猎物,当距离猎物足够近时,α指挥β,δ狼对猎物进行围攻,并召唤周围的ω狼对猎物进行攻击,当猎物移动时,狼群包围圈也随之移动,直到捕获猎物。GWO算法的原理图如图5-7所示。图中Dα,Dβ,Dδ,表示狼到α,β,δ狼的距离,C1,C2,C3表示狼的位置对猎物影响的随机权重,a1,a2,a3表示收敛因子。算法通过包围、追捕、攻击三个阶段进行捕猎,最终捕获猎物即获得全局最优解。卞等[36]将该方法用于玉米样本的
灰狼优化算法(GWO)是受灰狼群体捕食过程的启发,由澳大利亚学者Mirjalili等[35]在2014年提出来的一种群体智能优化算法。灰狼群居,在捕猎过程中它们分工明确、共同合作进行捕猎。领导能力最强的灰狼被记为α,主要负责捕猎过程中的决策部分及管理狼群。剩下的灰狼个体按社会等级被依次记为β,δ和ω。其中β狼和δ狼是等级依次排在后面的两个个体,捕猎中它们会协助α狼对灰狼群进行管理和辅助参与捕猎过程中的决策问题。剩余的狼群被定义为ω,其主要职责是平衡灰狼种群的内部关系及协助α,β,δ对猎物进行攻击。在整个捕猎过程中,首先由α狼带领狼群搜寻、追踪猎物,当距离猎物足够近时,α指挥β,δ狼对猎物进行围攻,并召唤周围的ω狼对猎物进行攻击,当猎物移动时,狼群包围圈也随之移动,直到捕获猎物。GWO算法的原理图如图5-7所示。图中Dα,Dβ,Dδ,表示狼到α,β,δ狼的距离,C1,C2,C3表示狼的位置对猎物影响的随机权重,a1,a2,a3表示收敛因子。算法通过包围、追捕、攻击三个阶段进行捕猎,最终捕获猎物即获得全局最优解。卞等[36]将该方法用于玉米样本的








