维权声明:本文为Ins_6b4d8c66原创作品,本作者与仪器信息网是该作品合法使用者,该作品暂不对外授权转载。其他任何网站、组织、单位或个人等将该作品在本站以外的任何媒体任何形式出现均属侵权违法行为,我们将追究法律责任。
1、背景介绍 随着微机电技术的发展,近几年,便携式近红外光谱仪被广泛应用于食品、饮料、医药、煤炭等各个领域,相较于传统的大型傅里叶变换光谱分析系统,其具有结构简单、成本低廉、携带方便、结果实时可见等优势,目前已成为光谱领域的热门产品。但是便携式近红外光谱仪易受光源、检测器、使用方法、环境条件等影响,使得采集的光谱数据稳定性差,精度低,进而造成预测结果不稳定、预测准确率低等问题。 为了解决上述问题,提升便携式近红外光谱分析结果的稳定性及准确性,目前行业内近红外光谱数据建模优化工作,主要集中于数据源筛选、预处理算法优化、模型筛选算法优化等基于PLS算法的单模型建模优化工作,此类建模算法主要适用于高精度的傅里叶近红外光谱仪。对于自身硬件分辨率较低的便携式近红外光谱仪,适用性较差。因此本帖在基于PLS算法建模的基础上,提出多模型加权预测的方法,以特定准则选取相对稳定、准确率较高的若干个光谱模型,结合模型自身系数进行加权预测的方式来提升便携式近红外光谱仪整体性能,进而提升便携式近红外光谱仪的预测稳定性及准确率。2、方法解析
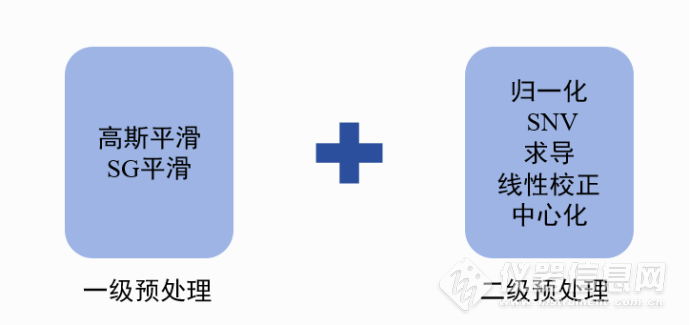
2.1样本集合划分 使用便携式近红外光谱仪采集400个待测样品,采用Kennard Stone(K-S)算法对样本进行划分,将样本划分为训练集(200个)、验证集(100个)、盲测集(100个)、避免人为划分样本的主观性。2.2光谱预处理 便携式近红外光谱仪采用常规的单一预处理方式效果不佳,本贴采用双预处理嵌套的方式对样品进行处理,其中第一级、第二级预处理均可设置不同的预处理参数,通过不同预处理方式,预处理参数的设置可以获取多种预处理结果。
![双预处理嵌套]()
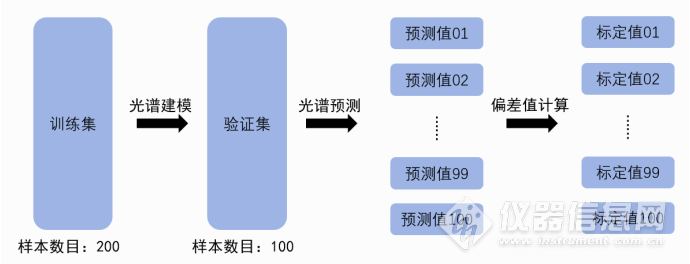
2.3光谱建模 近红外光谱定量分析建模方法包括多元线性回归(MLR)、主成分回归(PCR)、偏最小二乘回归(PLS)、人工神经网络(ANN)和支持向量机(SVM)等。其中,PLS算法应用最为广泛,选用PLS算法进行建模。通过多种预处理结果、不同PLS主成分数选择组合建立多个光谱定量分析模型,若设定一级预处理为M种,二级预处理为N种,PLS主成分数选择为T种,则通过不同排列组合可以建立合计M*N*T个光谱定量分析模型。
![多种建模方式]()
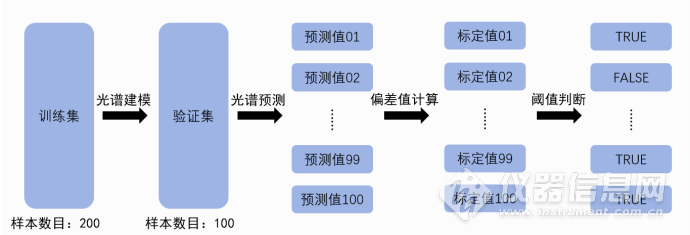
2.4光谱模型选择 基础模型一:在上述建立的大量光谱定量分析模型中,选择光谱模型最通用的两大表征系数,即模型相关系数(R2值)以及均方根误差(RMSECV值)进行基础模型筛选,选择模型相关系数最大的模型为基础模型A,模型均方根误差最小的模型为基础模型B。 基础模型二:在基础模型一中引入验证集,通过训练集建立的多个光谱模型对验证集进行预测,将预测值与验证集标定值进行计算,获取偏差值,选择偏差值最小的光谱模型为基础模型C。
![基础模型C]()
基础模型三:在基础模型二中引入准确率,在近红外快检的实际应用中,对于预测偏差值在一定阈值范围内的样本定义为准确预测样本,若超出阈值则为预测错误样本,选择准确率最高的光谱模型为基础模型D。
![基础模型D]()
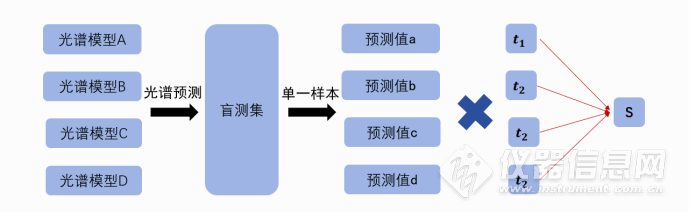
2.5权重系数计算 光谱模型不同,对盲测样本的预测能力不同,结合光谱模型的模型相关系数(R2值)或者均方根误差(RMSECV值)计算各个模型的预测权重,以模型相关系数为例:Ti=Ri/(R1+R2+R3+R4)
其中,R1为基础模型A的模型相关系数,R2为基础模型B的模型相关系数,依此类推。Ti为各个基础模型对应权重系数。2.6多模型加权预测 分别采用光谱基础模型A、B、C、D对盲测集100个样本进行预测,以盲测集单个样本为例,四个光谱模型对应获取四个预测值a、b、c、d ,结合权重系数计算最终单一预测值S:S=a*T1+b*T2+c*T3+d*T4
![多模型加权预测]()
3、实际应用
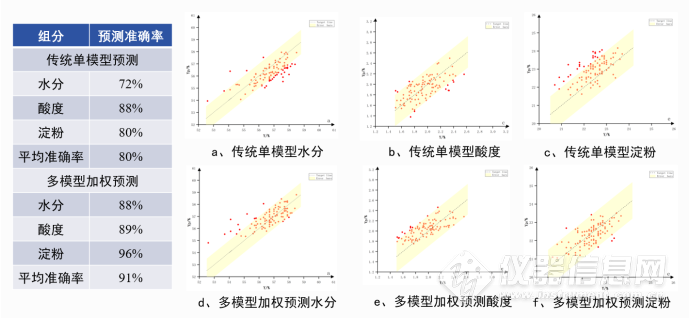
3.1硬件信息 硬件设备为四川长虹研发的PV800-III便携式近红外光谱仪,光谱仪波段范围为1350nm-2150nm,采样间隔为6nm,尺寸为Φ100mm×76.8mm,重量约750g。3.2样本采集: 采集400个酒醅样品,其中酒醅水分、淀粉、酸度等理化指标均由车间经验丰富化验员按常规化学方法测定所得。3.3分析对比 结合酒醅常用的光谱预处理算法及PLS单模型建模算法对本应用中酒醅数据进行建模,通过多种预处理组合优化,有效剔除光谱数据中的大量无用信息,并结合PLS算法,将高维光谱数据进行有效降维,提升光谱数据的有效性及准确度。最后以RMSECV作为模型筛选指标,利用筛选的最优模型对100条未知样本进行模型外验证,图a~c依次给出了传统单模型水分、酸度、淀粉3个指标的模型外预测分布情况,图中横坐标为标定值,纵坐标为预测值,黄色区域为模型允许的误差范围(水分、淀粉允许误差为绝对偏差±1,酸度允许误差范围为绝对偏差±0.3),采用基于多模型加权预测的近红外定量分析方法对上述酒醅光谱数据进行建模,利用筛选的多个光谱模型对相同的100条未知样本进行加权预测,图d~f依次依次给出了多模型加权预测方法水分、酸度、淀粉3个指标的模型外预测分布情况。
![酒醅定量分析]() 多模型加权预测方法相较于传统单模型预测方法,各指标准确率均有不同幅度提升,3个指标准确率平均提升约11%。各指标准确率均达到了企业车间应用要求。4、结论 利用便携式近红外光谱仪,分别以传统单模型建模方法、多模型加权预测方法进行酿酒车间酒醅各成分光谱建模,并对100个未知样本进行模型外预测分析。结果表明,基于多模型加权预测的近红外定量分析方法,可以有效弥补便携式近红外光谱仪在采样精度、稳定性等方面的不足。相较于单模型建模预测结果,多模型加权预测方法将酒醅样本各成分预测准确率平均提升了约11%,甚至可有效逼近大型傅里叶光谱仪设备预测效果,是一种可以在便携式近红外光谱快检领域推广应用的实用方法。
多模型加权预测方法相较于传统单模型预测方法,各指标准确率均有不同幅度提升,3个指标准确率平均提升约11%。各指标准确率均达到了企业车间应用要求。4、结论 利用便携式近红外光谱仪,分别以传统单模型建模方法、多模型加权预测方法进行酿酒车间酒醅各成分光谱建模,并对100个未知样本进行模型外预测分析。结果表明,基于多模型加权预测的近红外定量分析方法,可以有效弥补便携式近红外光谱仪在采样精度、稳定性等方面的不足。相较于单模型建模预测结果,多模型加权预测方法将酒醅样本各成分预测准确率平均提升了约11%,甚至可有效逼近大型傅里叶光谱仪设备预测效果,是一种可以在便携式近红外光谱快检领域推广应用的实用方法。