珠峰案例中误差类别困扰的全解析
武汉大学 叶晓明
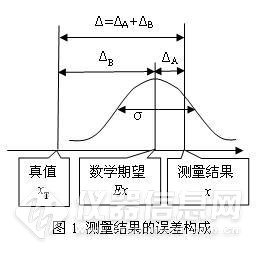
我多次用图1说明测量结果
x给出后Δ
A和Δ
B都是偏差,且都有各自的方差,没有性质差异,不存在分类问题。但总有人认为Δ
A重复测量会变化而Δ
B不会,它们有性质差异,Δ
B没有方差是系统误差,而Δ
A是随机误差。即使我以珠峰高程案例说明珠峰高程结果与其真值之差是个恒定的偏差,精度和恒定偏差联系在一起存在逻辑矛盾,但仍然有人要纠结未来重复测量珠峰高程这个恒差会发散。无可奈何,还得再次写点东西正面回应这种重复测量论。
![]()
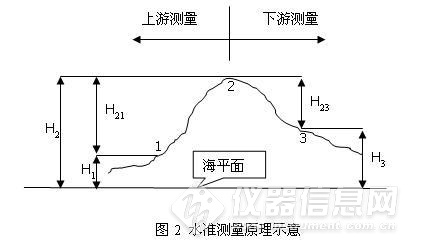
下图2是一个水准高程的大体测量过程,实际就是一个高程量值溯源链。
珠峰顶点相当于这里的2号点,1号点是用于测量2号点高程的参考基准点,其高程值为H
1,来自于更早的先前测量,然后通过对1、2二个水准点的高差H
21的测量利用公式H
2=H
1+H
21换算出2号点的高程。这些测量过程称为上游测量,上游测量是获得2号点的高程值H
2和对其误差ΔH
2做出评价的过程。
3号水准点是一个另外需要测量高程的水准点,它的高程以2号点的高程H
2为基准,通过测量高差值H
23利用公式H
3=H
2-H
23而获得。这一测量过程称为下游测量,下游测量是获得3号点的高程值H
3和对其误差ΔH
3做出评价的过程。
![]()
先看上游测量。
测量方程:H
2=H
1+H
21 于是误差方程:ΔH
2=ΔH
1+ΔH
21 显然这里的ΔH
21就是图1中的Δ
A,ΔH
1就是图1中的Δ
B。现在有人纠结重复测量时ΔH
21会随机变化而ΔH
1不会,所以ΔH
1是系统误差ΔH
21是随机误差。
姑且暂时不做分析,看完下游测量再说。
下游的测量方程是:H
3=H
2-H
23 于是误差方程:ΔH
3=ΔH
2-ΔH
23 显然这里的ΔH
23就是图1中的Δ
A,ΔH
2就是图1中的Δ
B。于是人们又开始纠结重复测量时ΔH
23会随机变化而ΔH
2不会,所以ΔH
2就变成了系统误差只有ΔH
23是随机误差。
可以看到了:
同样一个误差ΔH2,在上游测量被认为既有系统误差又有随机误差,而下游则认为只是一个纯粹的系统误差;而对于测绘领域给出的精度的概念逻辑而言,误差ΔH2则甚至是纯粹的随机误差。各说各话,纠缠不清了。
问题在哪?已经很清楚了:所谓的重复测量都是采用选择性失明的方式进行。
请看,所谓重复测量珠峰高程H
2=H
1+H
21,实际只是对高差H
21进行重复测量,而根本没有对H
1进行重复测量;所谓对3号水准点的高程H
3=H
2-H
23进行重复测量,实际只是对高差H
23进行重复测量,而根本没有对H
2进行重复测量。就这么简单的道理,
你对什么量重复测量,什么量才可能离散;你人为固定了某些量,它们当然无法离散。 一个测量结果是上游所有测量(追溯到量的定义)共同完成的,既然要纠缠重复测量,那当然就应该是上游测量整体地重复。纠缠于局部重复无异于坐井观天,当然就有失公允了。
重复测量的目的是获取误差统计评估所需要的误差样本,但前提是,对什么误差进行重复统计,获得的就是那个误差的概率分布评价;没有对某个误差进行重复统计,就不能获得其概率分布评价,但并不意味着这个误差的概率分布就不存在!特别是先前的上游测量已经给出了它的概率分布的时候,的确不一定需要再去重新统计,但没有理由用选择性失明的办法去否认别人的已经做出的统计评价。
所以,所谓”Δ
A重复测量会变化而Δ
B不会”实际是人为只做Δ
A的发散统计而没有做Δ
B的发散统计,而且忽视和否认了先前测量对Δ
B所做的统计评价σ(Δ
B)的本来存在。所谓系统误差Δ
B实际是上游测量的所谓随机误差,根本就不存在不遵循随机分布的问题(只是图1中没有把它的随机分布画出来),跟当前的测量误差Δ
A完全对等!
珠峰的测量早完成了,测量结果值已经确定,该统计该分析的标准偏差指标也都已经由它的测量者给出了,再去纠缠可以继续重复测量本来就已无必要。
总之,上述水准高程的溯源过程中,每个单一误差实际都有它的分散区间,都有方差评价其概率范围。这样,根据误差方程:ΔH
2=ΔH
1+ΔH
21,就一定有方差合成方程:σ
2(ΔH
2)=σ
2(ΔH
1)+σ
2(ΔH
21);根据误差方程:ΔH
3=ΔH
2-ΔH
23,就一定有方差合成方程:σ
2(ΔH
3)=σ
2(ΔH
2)+σ
2(ΔH
23);根据误差方程:Δ=Δ
A+Δ
B,就一定有方差合成方程:σ
2(Δ)=σ
2(Δ
A)+σ
2(Δ
B)。这些标准偏差就是相应的误差(偏差)的所有可能取值的分散区间的评价,叫做不确定度,并不存在什么误差没有分散区间的情况,所有误差的性质完全对等,不存在分类的问题。测量结果的误差评价中实际就没有误差分类概念精度、准确度(正确度)的什么事。
2018 3 31
![]()