维权声明:本文为byron1111原创作品,本作者与仪器信息网是该作品合法使用者,该作品暂不对外授权转载。其他任何网站、组织、单位或个人等将该作品在本站以外的任何媒体任何形式出现均属侵权违法行为,我们将追究法律责任。
标准曲线权重因子的使用
我们在分析工作中,经常会接触到外标或者内标标准曲线。标准曲线的获取是基于最小二乘原理,我们可能也比较熟悉这一点。
在此,我再稍作赘述吧。
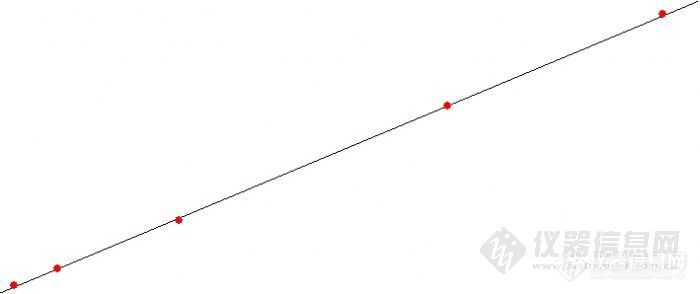
假设已经获得色谱数据点(Ci,Ai)(i =1,2……n),任意一条工作曲线的方程可以表示如下:A* = a + b × C那么每个数据点和标准曲线对应点的误差为:Ai - A* = Ai - a - b × Ci定义各个点误差平方和为Q*:Q* = [img=13,20]file:///C:\Users\BYRON1~1\AppData\Local\Temp\ksohtml\wps_clip_image-10473.png[/img]
Σ(Ai – a - b ×Ci)2 [img=13,20]file:///C:\Users\BYRON1~1\AppData\Local\Temp\ksohtml\wps_clip_image-17870.png[/img]
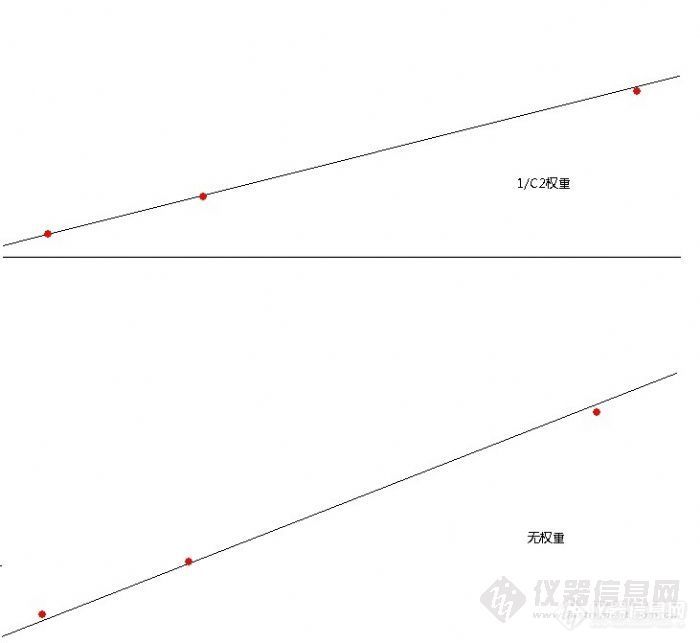
回归曲线就是使得Q*最小的曲线。如图所示
![]()
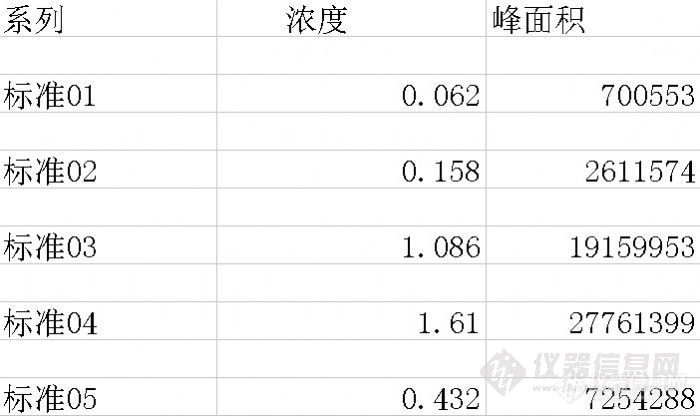
我们下面来看一个具体的案例:我们获得5个实验数据,峰面积和浓度分别如下
![]()
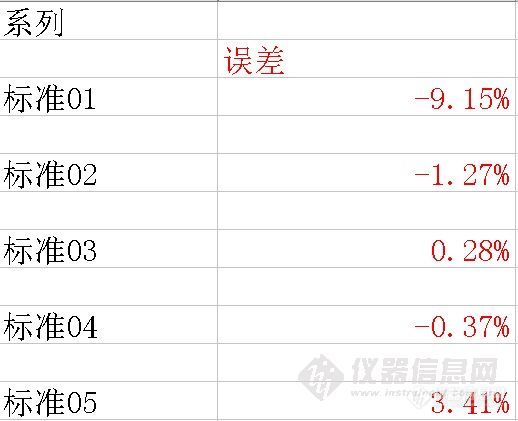
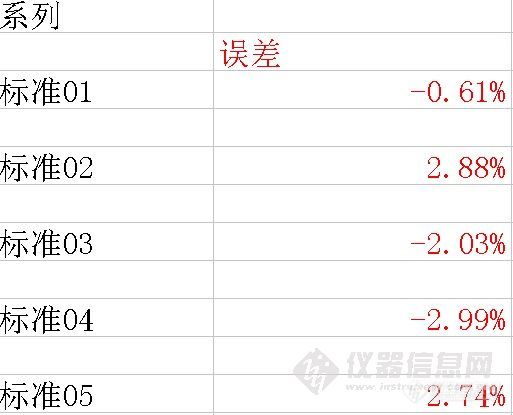
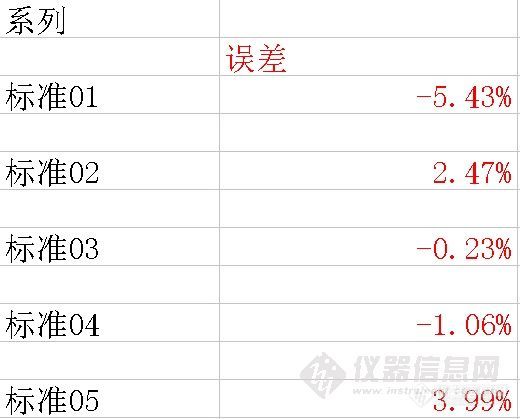
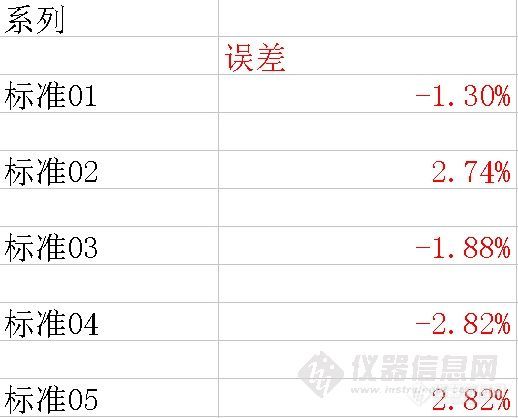
用工作站的默认参数获得标准曲线。然后将标准01、02、03、04、05各个数据回带入标准曲线,考察该点和标准曲线对应点的相对误差。结果如下:
![]()
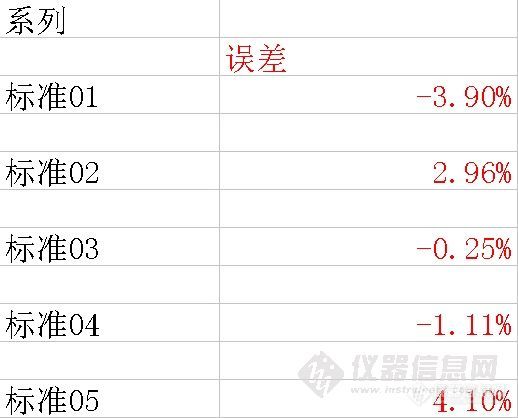
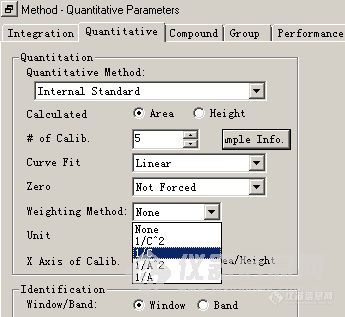
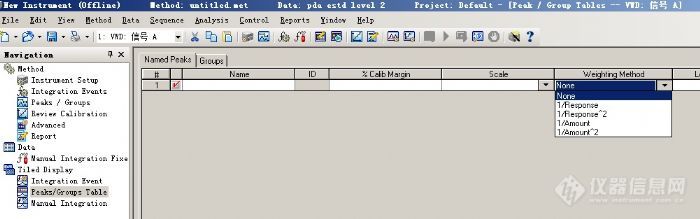
可以看出,低浓度的标准点相对误差较大,或者说该点偏离校准曲线较多(当然需要排除标准样品浓度不良的问题)。为什么会出现这个现象呢?我们回过头来在考察标准曲线的原理,数据点和标准曲线对应点的误差平方之和最小,即所有的数据点都比较逼近标准曲线。但是对于每一个数据点来将,总体误差较小,并不意味着每个数据点的相对误差最小。如果分析感兴趣的样品总是分布在较低浓度点附近,采用加权的校准曲线就比较重要了。我们分别使用1/A、1/C、1/A2 、1/C2 做权重,得到如下的数据结果。